FPN
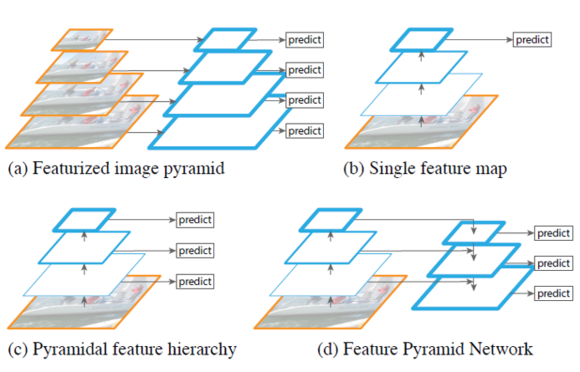
🌑 Introduction 아래 그림 (a)와 같이 기존의 객체검출은 hand-engineered features를 이용하여 image pyramids를 구성하고 각 pyramid에서 feature를 계산한 후 모든 위치에서 객체 유무를 판단하는 방법이였다. 이와 다르게 최근의 convNet 기반의 객체검출은 convNet 자체가 scale에 강인하기도 하지만 빠른 객체검출을 위해 1개의 scale만을 이용하였다. 하지만 convNet 의 scale 변화에 강인성에는 한계가 있고 최근의 ImageNet, COCO detection challenges 에서는 featurized image pyramid 기반으로 multi-scale testing을 이용하였다. 이러한 방법들은 수행시간이 오래 걸리며, 학습 시에도 많은 메모리가 필요하다는 단점이 있다. 이를 해결하기 위한 방법으로 그림 (c)와 같은 pyramidal feature hierarchy가 있다. 이 network는 서로 다른 scale을 갖는 feature map을 이용하여 검출에 사용한다. 대표적인 방법이 SSD 이다. SSD 는 계산한 feature map을 다시 사용하여 higher layer를 계속 생성한다. SSD는 이미 계산한 higher-resolution maps을 검출할 때 1회만 사용한다. 하지만 이러한 feature map은 작은 객체에 대한 정보를 많이 담고 있으므로 1회가 아닌 여러 번 사용하는 것이 작은 객체를 검출할 때 도움이 된다. 이 논문의 목표는 convNet’s feature hierarchy의 pyramidal shape을 활용하는데 어떻게 활용하느냐 바로 모든 scale 에서 강력한 semantics을 갖도록 하겠다는 것이다. 그럼 어떻게 그 목적을 달성하느냐? è Network 구조는 top-down과 lateral connection(측면에서 연결)에 있다. 그림 (d)와 같은 구조를 통해 semantic이 강한 low-resolution(widt...



