Convolutional Sequence to Sequence Learning
초기에 https://arxiv.org/pdf/1408.5882.pdf 와 같이 CNN을 NLP에 적용한 방법들이 있었다.
이러한 방법들은 단순하게 CNN을 NLP에 적용해서 성능이 그다지 좋지 않았고 한 동안 CNN을 이용한 방법들은 주류에서 멀어지게 되었고 RNN을 반드시 사용해야 하는 것 같이 생각되었다. 구글의 NMT를 보면 Bidirectional RNNs과 attention mechanism, LSTM은 반드시 사용되어야 하는 것처럼 생각되었다.
내가 NLP 전공자는 아니지만 attention 이라는게 처음 나온 이유가 Encoder-decoder(seq-to-seq)에서 모든 encoder의 정보가 하나의 vector로 정리되고 이를 통해 decoder를 할 경우 input sentence가 길어질 수록 메모리의 제약이 온다는 점이다. 또한 학습도 어려워진다. 이를 해결하고자 attention model이 제안되었다. 나는 CNN만 주로 다루다 보니 NLP에 CNN을 적용하는거 자체가 성능에 제약이 있는 것이 아니라 잘 적용하면 성능은 올라갈 것이라고 생각이 들었다. 딥러닝을 각 도메인에 적용했을 때 어떻게 적용할 지 몰라 단순하게 mnist처럼 다루는 방식은 성능이 기존 보다 높지 않지만 각 도메인에 적절하게 네트워크를 구성하면 결국에는 성능이 올라가는 것이 요 몇 년 사이에 일어나는 일이다.
그래서 attention을 처음 읽었을 때 각 sequence의 정보를 저렇게 어차피 저장해서 attention을 이용해서 사용할 것이라면 CNN으로 충분히 대체 가능하다는 생각이 들었다.
오늘 살펴 본 논문처럼 기존보다 성능도 좋은 결과물이 나왔다는 것이 상당히 고무적이다.
Pixel RNN이 결국 pixel CNN++ 로 발전하는 것처럼 이제 NLP도 CNN이 대세인 시대가 오는 것인가. 그런 경우 정말 네트워크만 잘 설계하면 NLP도 나 같은 영상처리만 딥러닝으로 한 사람도 할 수 있는 시대가 오는 것 아닌가라는 ...(도메인 간의 벽이 무너진다는 얘긴 벌써 나온지 꽤 됐다.) 물론 상품화를 위해서는 엄청난 노가다가 여기에도 필요하겠지만...
자 이제 이 논문을 살펴보자.
대략적인 개념만 살펴보면 먼저 English source sentence가 encoding 된다.
그리고 German target words와 이 source encoding 사이에 가운데 Dot products와 같이 attention value가 계산된다.
이 attention 계산은 간단하게 source encoding과 target decoder context representations 사이의 dot product이다.
그 다음 dot product에서 계산된 값들과 target decoder context representations 을 더해줘서 target words를 예측하는데 사용한다.

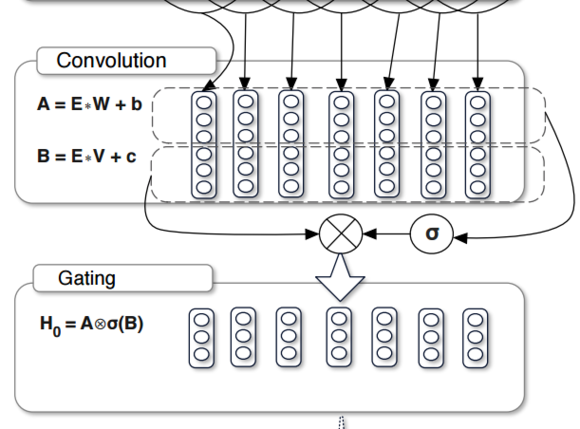
여기서 사용된 sigmoid와 multiplicative를 Gated Linear Units라고 한다.
사실 이와 비슷한 개념이 Conditional Image Generation with PixelCNN Decoders에 이미 나왔고 6개월 뒤에 발표된 Language Modeling with Gated Convolutional Networks
에서 GLU가 나왔다.
GLU의 경우 단순하게 아래 그림과 같이 표현된다.
LSTM에서도 sigmoid는 gate로 사용한 것과 같이 여기서도 sigmoid는gate로 사용된다.
input A의 정보를 얼만큼 사용할 것인지를 조절한다.
gated pixel cnn에서는 아래와 같이 이용한다.
역시 딥러닝이 영상 기반으로 발전해서 다른 분야로 확대되는 것 같다라는 생각이다.
물론 구현하고 확인하기가 좋은 점도 있지만.

수식이 있긴 하지만 CNN이 들어가서 그런지 생각보다 network 구조가 간단하다.
이러한 방법들은 단순하게 CNN을 NLP에 적용해서 성능이 그다지 좋지 않았고 한 동안 CNN을 이용한 방법들은 주류에서 멀어지게 되었고 RNN을 반드시 사용해야 하는 것 같이 생각되었다. 구글의 NMT를 보면 Bidirectional RNNs과 attention mechanism, LSTM은 반드시 사용되어야 하는 것처럼 생각되었다.
내가 NLP 전공자는 아니지만 attention 이라는게 처음 나온 이유가 Encoder-decoder(seq-to-seq)에서 모든 encoder의 정보가 하나의 vector로 정리되고 이를 통해 decoder를 할 경우 input sentence가 길어질 수록 메모리의 제약이 온다는 점이다. 또한 학습도 어려워진다. 이를 해결하고자 attention model이 제안되었다. 나는 CNN만 주로 다루다 보니 NLP에 CNN을 적용하는거 자체가 성능에 제약이 있는 것이 아니라 잘 적용하면 성능은 올라갈 것이라고 생각이 들었다. 딥러닝을 각 도메인에 적용했을 때 어떻게 적용할 지 몰라 단순하게 mnist처럼 다루는 방식은 성능이 기존 보다 높지 않지만 각 도메인에 적절하게 네트워크를 구성하면 결국에는 성능이 올라가는 것이 요 몇 년 사이에 일어나는 일이다.
그래서 attention을 처음 읽었을 때 각 sequence의 정보를 저렇게 어차피 저장해서 attention을 이용해서 사용할 것이라면 CNN으로 충분히 대체 가능하다는 생각이 들었다.
오늘 살펴 본 논문처럼 기존보다 성능도 좋은 결과물이 나왔다는 것이 상당히 고무적이다.
Pixel RNN이 결국 pixel CNN++ 로 발전하는 것처럼 이제 NLP도 CNN이 대세인 시대가 오는 것인가. 그런 경우 정말 네트워크만 잘 설계하면 NLP도 나 같은 영상처리만 딥러닝으로 한 사람도 할 수 있는 시대가 오는 것 아닌가라는 ...(도메인 간의 벽이 무너진다는 얘긴 벌써 나온지 꽤 됐다.) 물론 상품화를 위해서는 엄청난 노가다가 여기에도 필요하겠지만...
자 이제 이 논문을 살펴보자.
대략적인 개념만 살펴보면 먼저 English source sentence가 encoding 된다.
그리고 German target words와 이 source encoding 사이에 가운데 Dot products와 같이 attention value가 계산된다.
이 attention 계산은 간단하게 source encoding과 target decoder context representations 사이의 dot product이다.
그 다음 dot product에서 계산된 값들과 target decoder context representations 을 더해줘서 target words를 예측하는데 사용한다.

여기서 사용된 sigmoid와 multiplicative를 Gated Linear Units라고 한다.
사실 이와 비슷한 개념이 Conditional Image Generation with PixelCNN Decoders에 이미 나왔고 6개월 뒤에 발표된 Language Modeling with Gated Convolutional Networks
에서 GLU가 나왔다.
GLU의 경우 단순하게 아래 그림과 같이 표현된다.
LSTM에서도 sigmoid는 gate로 사용한 것과 같이 여기서도 sigmoid는gate로 사용된다.
input A의 정보를 얼만큼 사용할 것인지를 조절한다.

gated pixel cnn에서는 아래와 같이 이용한다.
역시 딥러닝이 영상 기반으로 발전해서 다른 분야로 확대되는 것 같다라는 생각이다.
물론 구현하고 확인하기가 좋은 점도 있지만.

수식이 있긴 하지만 CNN이 들어가서 그런지 생각보다 network 구조가 간단하다.


댓글
댓글 쓰기