FPN
🌑 Introduction
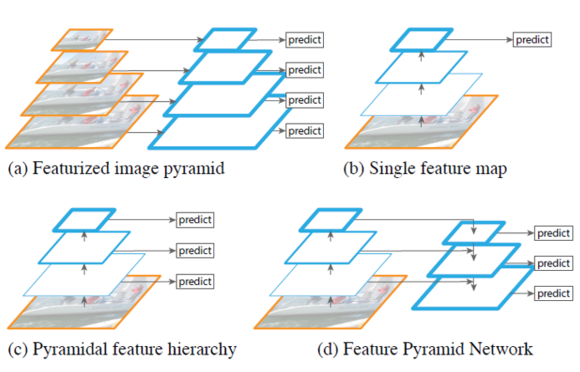
아래 그림 (a)와 같이 기존의 객체검출은 hand-engineered features를 이용하여 image pyramids를 구성하고 각 pyramid에서 feature를 계산한 후 모든 위치에서 객체 유무를 판단하는 방법이였다. 이와 다르게 최근의 convNet 기반의 객체검출은 convNet 자체가 scale에 강인하기도 하지만 빠른 객체검출을 위해 1개의 scale만을 이용하였다.
하지만 convNet 의 scale 변화에 강인성에는 한계가 있고 최근의 ImageNet, COCO detection challenges 에서는 featurized image pyramid 기반으로 multi-scale testing을 이용하였다. 이러한 방법들은 수행시간이 오래 걸리며, 학습 시에도 많은 메모리가 필요하다는 단점이 있다.
이를 해결하기 위한 방법으로 그림 (c)와 같은 pyramidal feature hierarchy가 있다. 이 network는 서로 다른 scale을 갖는 feature map을 이용하여 검출에 사용한다. 대표적인 방법이 SSD 이다. SSD 는 계산한 feature map을 다시 사용하여 higher layer를 계속 생성한다. SSD는 이미 계산한 higher-resolution maps을 검출할 때 1회만 사용한다. 하지만 이러한 feature map은 작은 객체에 대한 정보를 많이 담고 있으므로 1회가 아닌 여러 번 사용하는 것이 작은 객체를 검출할 때 도움이 된다.
이 논문의 목표는 convNet’s feature hierarchy의 pyramidal shape을 활용하는데 어떻게 활용하느냐 바로 모든 scale 에서 강력한 semantics을 갖도록 하겠다는 것이다. 그럼 어떻게 그 목적을 달성하느냐?
è Network 구조는 top-down과 lateral connection(측면에서 연결)에 있다. 그림 (d)와 같은 구조를 통해 semantic이 강한 low-resolution(width, height가 low)과 semantic이 약한 high-resolution을 연결하여 사용한다. (semantic은 top layer에서 강함)
제안하는 구조와 비슷하게 top-down과 skip-connections을 사용하는 연구들은 아래와 같다.
① Object detection networks on convolutional feature maps[27]
② Recombinator networks: Learning coarse-to-fine feature aggregation[16]
③ Laplacian pyramid reconstruction and refinement for semantic segmentation[8]
④ Stacked hourglass networks for human pose estimation[25]
2. Feature Pyramid Networks
우리의 목적은 ConvNet’s pyramidal feature hierarchy((that has semantics from low to high levels)을 향상시키고, 전체 계층에 걸쳐 high-level semantics을 갖는 feature pyramid를 만드는 것이다. Feature Pyramid Network는 RPN과 같이 작동한다. 또한 FPNs을 instance segmentation proposals에 이용 가능 하도록 일반화 시켰다.
제안하는 Network의 구조는 bottom-up pathway, a top-down pathway, and lateral
Connections이 포함되어 있다.
◆ Bottom-up pathway
Bottom-up pathway 는 scaling step 2를 갖는 여러 scales에서의 계층적 feature maps으로 구성된 ConvNet의 feed-forward 연산이다. 이 구조는 동일한 output maps resolution을 갖는 layers들이 존재하며 이러한 layers들은 stage라고 한다. 이 stage는 size가 달라지면서 다음 stage로 넘어간다고 보면 된다.
제안하는 feature pyramid에서는 각 stage마다 1개의 pyramid level을 갖도록 한다. 각 stage의 last layer의 output maps을 이용하여 pyramid의 feature를 강화한다. ResNet을 예로 들면, last residual blocks인{C2, C3, C4, C5} 을 이용하게 되는데 이는 각각 conv2, conv3, conv4, conv5 이며 각각 input image 대비 (4, 8, 16, 32)의 stride를 갖는다 즉 원본 대비 크기가 conv2는 1/4로 줄어든다는 것이다.
◆ Top-down pathway and lateral connections
Top-down pathway는 higher pyramid levels의 feature map들은 semantically 강인한 반면, spatially는 약한데 이를 upsampling 하여 higher resolution을 갖게 만드는 것이 핵심이다. 이 feature는 bottom-up pathway에서 생성된 feature maps을 아래 그림과 같이 측면 연결을 통해 더 강인해진다. 이 feature는 semantically 약하지만, spatially 강인하다. 이 2개의 feature maps은 element wise sum으로 1개의 feature map이 되고 여기서 3x3 convolution 을 적용하여 최종 feature map을 생성한다.

3. Applications
3.1. Feature Pyramid Networks for RPN
RPN 은 top of a single-scale convolutional feature map에서 object/nonobject binary classification 과 bounding box regression을 수행한다. 자세히 설명하기 위해 그림을 이용한다.

Conv5_3 output map에 대해 3x3 convolution을 적용하면 512 개의 output number를 갖는 feature map이 생성된다. 여기에 object/nonobject binary classification을 위해 1x1 conv 연산을 적용한다. 이 때 output number는 anchors에 따라 아래 공식으로 정해진다. Output number = 2(bg/fg) * 9(anchors number) = 18
즉 conv5_3이 32 x 32 size에 512 개의 output number를 갖는다면 여기에 1x1 convolution(512 x 18 개의 parameter 수를 갖음) 적용하면 32x32x18 개를 갖는 output map 이 생성되며 이것을 통해 9개 anchors에 대해 bg/fg를 판별하게 된다. 각 anchors는 2개의 bg/fg 정보를 갖는 32 x 32 size의 output map이 있고 이 중 큰 것을 bg/fg 판단의 근거로 한다. 즉 32 x 32 x 9 개에 대한 bg/fg 정보가 나온다.
bounding box regression 역시 마찬가지 과정을 갖는다. 차이는 bbox를 위한 x, y, w, h 즉 4개와 anchors 수 9 즉 36 개의 output map number를 갖는 다는 것이다.
자 이를 영어로 간단히 표현하면 “This is realized by a 3x3 convolutional layer followed by
two sibling 1x1 convolutions for classification and regression, which we refer to as a network head.”
그럼 기존의 RPN 대신 FPN을 어떻게 적용하느냐 제안하는 feature pyramid의 각 stage의 last layer 마다 위와 동일한 design(classification and regression) 을 적용하는 것이다.
Anchors의 size는 {32^2, 64^2, 128^2, 256^2, 512^2} 와 갖고 aspect ratio는 {1:2, 1:1, 2:1} 이다. 총 15개의 anchors가 존재한다. 실제로 512 x 512 size를 갖는 anchors는 사용하지 않는다. 여기서 착각할 수 있는 것은 위 size를 모든 levels에 적용하는 게 아니라 각 level 마다 다른 size를 적용한다는 것이다. 즉 P2 에는 32 x 32 만 이용한다는 의미이다. 원래 faster-rcnn 논문에서는 3 scale x 3 aspect ratio를 적용하여 9개였는데 여기서는 scale이 feature pyramid를 통해 해결됐기 때문에 3 scale은 사용하지 않는다.
Anchors와 ground-truth(GT) 사이의 IoU가 0.7 이상이면 positive, 0.3 이하이면 negative로 처리한다. GT의 scales에 따라 직접적으로 pyramid level에 지정하는 것이 아니라 anchors에 지정된다. 즉 IoU에 따라 알아서 anchors와 연결되니 기존의 Faster-Rcnn과 동일하다는 의미이다.
3.2. Feature Pyramid Networks for Fast RCNN
자 이제 FPN에 의해 ROI가 정해졌다면 아래 그림과 같이 classifcation과 bbox regression을 할 차례이다. 아래 roi_pool5는 conv5_3에서 FPN에서 계산된 roi를 기반으로 feature를 pooling하는 단계이다. 이 layer의 이름은 roi_pool5 이고 conv5_3과 roi를 bottom으로 받고 roi_pooling parameter는 7 x 7 이다. 즉 roi가 어떻든지 간에 7x7 size를 갖는 output map을 생성한다는 것이다.

마지막으로 성능을 확인해보자.
아래는 COCO detection benchmark에서 단일 모델을 적용했을 때 결과이다.

2016도 winner인 G-RMI 대비 성능 개선이 있음을 알 수 있다.
아래 그림 (a)와 같이 기존의 객체검출은 hand-engineered features를 이용하여 image pyramids를 구성하고 각 pyramid에서 feature를 계산한 후 모든 위치에서 객체 유무를 판단하는 방법이였다. 이와 다르게 최근의 convNet 기반의 객체검출은 convNet 자체가 scale에 강인하기도 하지만 빠른 객체검출을 위해 1개의 scale만을 이용하였다.
하지만 convNet 의 scale 변화에 강인성에는 한계가 있고 최근의 ImageNet, COCO detection challenges 에서는 featurized image pyramid 기반으로 multi-scale testing을 이용하였다. 이러한 방법들은 수행시간이 오래 걸리며, 학습 시에도 많은 메모리가 필요하다는 단점이 있다.
이를 해결하기 위한 방법으로 그림 (c)와 같은 pyramidal feature hierarchy가 있다. 이 network는 서로 다른 scale을 갖는 feature map을 이용하여 검출에 사용한다. 대표적인 방법이 SSD 이다. SSD 는 계산한 feature map을 다시 사용하여 higher layer를 계속 생성한다. SSD는 이미 계산한 higher-resolution maps을 검출할 때 1회만 사용한다. 하지만 이러한 feature map은 작은 객체에 대한 정보를 많이 담고 있으므로 1회가 아닌 여러 번 사용하는 것이 작은 객체를 검출할 때 도움이 된다.
이 논문의 목표는 convNet’s feature hierarchy의 pyramidal shape을 활용하는데 어떻게 활용하느냐 바로 모든 scale 에서 강력한 semantics을 갖도록 하겠다는 것이다. 그럼 어떻게 그 목적을 달성하느냐?
è Network 구조는 top-down과 lateral connection(측면에서 연결)에 있다. 그림 (d)와 같은 구조를 통해 semantic이 강한 low-resolution(width, height가 low)과 semantic이 약한 high-resolution을 연결하여 사용한다. (semantic은 top layer에서 강함)

제안하는 구조와 비슷하게 top-down과 skip-connections을 사용하는 연구들은 아래와 같다.
① Object detection networks on convolutional feature maps[27]
② Recombinator networks: Learning coarse-to-fine feature aggregation[16]
③ Laplacian pyramid reconstruction and refinement for semantic segmentation[8]
④ Stacked hourglass networks for human pose estimation[25]
2. Feature Pyramid Networks
우리의 목적은 ConvNet’s pyramidal feature hierarchy((that has semantics from low to high levels)을 향상시키고, 전체 계층에 걸쳐 high-level semantics을 갖는 feature pyramid를 만드는 것이다. Feature Pyramid Network는 RPN과 같이 작동한다. 또한 FPNs을 instance segmentation proposals에 이용 가능 하도록 일반화 시켰다.
제안하는 Network의 구조는 bottom-up pathway, a top-down pathway, and lateral
Connections이 포함되어 있다.
◆ Bottom-up pathway
Bottom-up pathway 는 scaling step 2를 갖는 여러 scales에서의 계층적 feature maps으로 구성된 ConvNet의 feed-forward 연산이다. 이 구조는 동일한 output maps resolution을 갖는 layers들이 존재하며 이러한 layers들은 stage라고 한다. 이 stage는 size가 달라지면서 다음 stage로 넘어간다고 보면 된다.
제안하는 feature pyramid에서는 각 stage마다 1개의 pyramid level을 갖도록 한다. 각 stage의 last layer의 output maps을 이용하여 pyramid의 feature를 강화한다. ResNet을 예로 들면, last residual blocks인{C2, C3, C4, C5} 을 이용하게 되는데 이는 각각 conv2, conv3, conv4, conv5 이며 각각 input image 대비 (4, 8, 16, 32)의 stride를 갖는다 즉 원본 대비 크기가 conv2는 1/4로 줄어든다는 것이다.
◆ Top-down pathway and lateral connections
Top-down pathway는 higher pyramid levels의 feature map들은 semantically 강인한 반면, spatially는 약한데 이를 upsampling 하여 higher resolution을 갖게 만드는 것이 핵심이다. 이 feature는 bottom-up pathway에서 생성된 feature maps을 아래 그림과 같이 측면 연결을 통해 더 강인해진다. 이 feature는 semantically 약하지만, spatially 강인하다. 이 2개의 feature maps은 element wise sum으로 1개의 feature map이 되고 여기서 3x3 convolution 을 적용하여 최종 feature map을 생성한다.

3. Applications
3.1. Feature Pyramid Networks for RPN
RPN 은 top of a single-scale convolutional feature map에서 object/nonobject binary classification 과 bounding box regression을 수행한다. 자세히 설명하기 위해 그림을 이용한다.

Conv5_3 output map에 대해 3x3 convolution을 적용하면 512 개의 output number를 갖는 feature map이 생성된다. 여기에 object/nonobject binary classification을 위해 1x1 conv 연산을 적용한다. 이 때 output number는 anchors에 따라 아래 공식으로 정해진다. Output number = 2(bg/fg) * 9(anchors number) = 18
즉 conv5_3이 32 x 32 size에 512 개의 output number를 갖는다면 여기에 1x1 convolution(512 x 18 개의 parameter 수를 갖음) 적용하면 32x32x18 개를 갖는 output map 이 생성되며 이것을 통해 9개 anchors에 대해 bg/fg를 판별하게 된다. 각 anchors는 2개의 bg/fg 정보를 갖는 32 x 32 size의 output map이 있고 이 중 큰 것을 bg/fg 판단의 근거로 한다. 즉 32 x 32 x 9 개에 대한 bg/fg 정보가 나온다.
bounding box regression 역시 마찬가지 과정을 갖는다. 차이는 bbox를 위한 x, y, w, h 즉 4개와 anchors 수 9 즉 36 개의 output map number를 갖는 다는 것이다.
자 이를 영어로 간단히 표현하면 “This is realized by a 3x3 convolutional layer followed by
two sibling 1x1 convolutions for classification and regression, which we refer to as a network head.”
그럼 기존의 RPN 대신 FPN을 어떻게 적용하느냐 제안하는 feature pyramid의 각 stage의 last layer 마다 위와 동일한 design(classification and regression) 을 적용하는 것이다.
Anchors의 size는 {32^2, 64^2, 128^2, 256^2, 512^2} 와 갖고 aspect ratio는 {1:2, 1:1, 2:1} 이다. 총 15개의 anchors가 존재한다. 실제로 512 x 512 size를 갖는 anchors는 사용하지 않는다. 여기서 착각할 수 있는 것은 위 size를 모든 levels에 적용하는 게 아니라 각 level 마다 다른 size를 적용한다는 것이다. 즉 P2 에는 32 x 32 만 이용한다는 의미이다. 원래 faster-rcnn 논문에서는 3 scale x 3 aspect ratio를 적용하여 9개였는데 여기서는 scale이 feature pyramid를 통해 해결됐기 때문에 3 scale은 사용하지 않는다.
Anchors와 ground-truth(GT) 사이의 IoU가 0.7 이상이면 positive, 0.3 이하이면 negative로 처리한다. GT의 scales에 따라 직접적으로 pyramid level에 지정하는 것이 아니라 anchors에 지정된다. 즉 IoU에 따라 알아서 anchors와 연결되니 기존의 Faster-Rcnn과 동일하다는 의미이다.
3.2. Feature Pyramid Networks for Fast RCNN
자 이제 FPN에 의해 ROI가 정해졌다면 아래 그림과 같이 classifcation과 bbox regression을 할 차례이다. 아래 roi_pool5는 conv5_3에서 FPN에서 계산된 roi를 기반으로 feature를 pooling하는 단계이다. 이 layer의 이름은 roi_pool5 이고 conv5_3과 roi를 bottom으로 받고 roi_pooling parameter는 7 x 7 이다. 즉 roi가 어떻든지 간에 7x7 size를 갖는 output map을 생성한다는 것이다.

마지막으로 성능을 확인해보자.
아래는 COCO detection benchmark에서 단일 모델을 적용했을 때 결과이다.

2016도 winner인 G-RMI 대비 성능 개선이 있음을 알 수 있다.


댓글
댓글 쓰기