Perceptual Generative Adversarial Networks for Small Object Detection
▣ 간략 소개
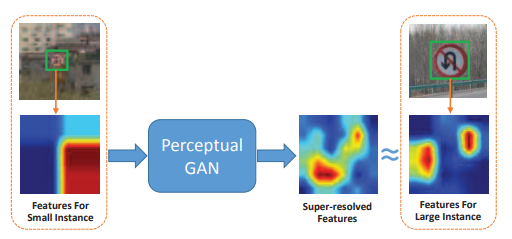
아래에서 "features for small instance"는 작은 객체에서 CNN layer의 윗 단에서 나온 feature이고 "features for large instance" 아래 그림과 같이 큰 객체에서 나온 feature이다. 작은 객체에서 나온 feature는 구분이 어려울 정도로 low resolution이다. 이것을 아래의 큰 객체에서 나온 feature처럼 만들어 주면 어떨까? 이게 이 논문의 중요 아이디어다.
▣ Perceptual GANs의 개요
이제 논문의 아이디어는 알았으니 자세히 network를 분석해보자.
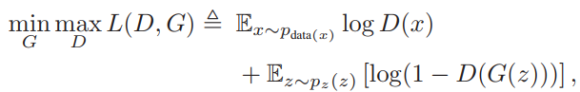
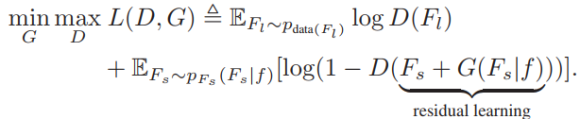
아래에서 "features for small instance"는 작은 객체에서 CNN layer의 윗 단에서 나온 feature이고 "features for large instance" 아래 그림과 같이 큰 객체에서 나온 feature이다. 작은 객체에서 나온 feature는 구분이 어려울 정도로 low resolution이다. 이것을 아래의 큰 객체에서 나온 feature처럼 만들어 주면 어떨까? 이게 이 논문의 중요 아이디어다.
▣ Perceptual GANs의 개요
이제 논문의 아이디어는 알았으니 자세히 network를 분석해보자.
- step1> 먼저, discriminator의 perception branch가 큰 객체만 포함하는 학습 이미지를 가지고 학습된다.
- step2> 그 다음 generator network는 작은 객체만 포함된 학습 이미지를 가지고 super-resolved large-object를 생성하도록 학습된다.
- step3> discriminator network의 adversarial branch가 step2 에서 생성한 super-resolved large-object 와 큰 객체의 feature를 구분하도록 학습된다.
▣ Perceptual GANs에 대한 상세 분석
아래는 일반적인 GAN의 수식이다. 이런 default 개념을 vanilla라는 표현을 써서 vanilla GAN이라고 한다.
아래는 일반적인 GAN의 수식이다. 이런 default 개념을 vanilla라는 표현을 써서 vanilla GAN이라고 한다.
보통 x는 real sample, z는 noise distribution에서 생성된 generator의 input vector이다. DC-GAN의 경우 100-d 이다.제안하는 Perceptual GANs에서는 x가 큰 객체이고, z는 작은객체가 된다아래 수식으로 표현된다.
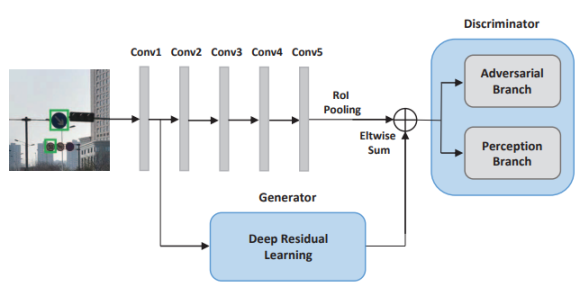
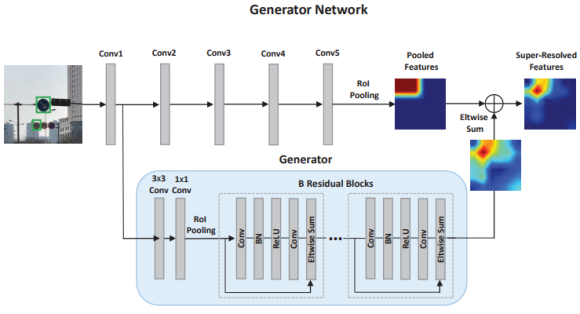
자세한 network에 대한 그림은 아래와 같다. 먼저 , generator를 보자.
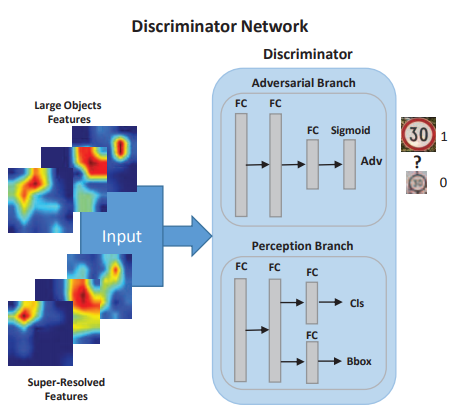
B Residual Blocks의 마지막 feature map dimension이 Conv5의 feature map과 동일하게 만들어서 eltwise sum이 가능하도록 한다.input image의 작은 객체는 RoI Pooling되어 B Residual Blocks의 output map과 eltwise sum을 하면 Super-Resolved Features가 만들어 진다. 이제 discriminator를 보자.discriminator network의 adversarial branch는 input이 large objects 에 속하는지 0~1 사이의 값을 sigmoid를 통해 계산한다.perception branch는 두 개의 task를 하는데 우리가 흔히 아는 object deteciton의 task와 동일하다. 즉 classification 와 bounding box regression을 수행한다.
▣ 성능
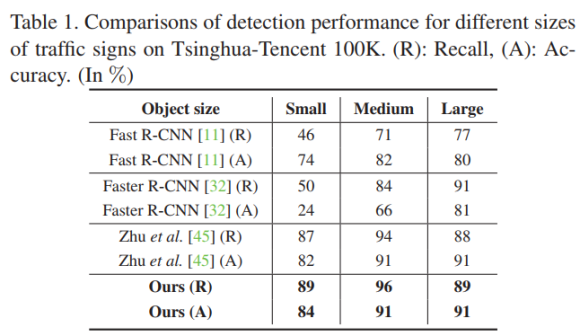
기존 SOTA는 Zhe Zhu "Traffic-Sign Detection and Classification in the Wild"였다. 이것보다 성능이 개선되었다.
기존 SOTA는 Zhe Zhu "Traffic-Sign Detection and Classification in the Wild"였다. 이것보다 성능이 개선되었다.


댓글
댓글 쓰기